Opětovné sestavení RAID s neznámou konfigurací pomocí entropie na úrovni bloků
Pole RAID (Redundant Array of Independent Disks - redundantní pole nezávislých disků) se hojně používá v systémech úložišť, aby se předešlo ztrátě dat v případě hardwarové závady na pevném disku a aby se zvýšil výkon I/O. V případě selhání řadiče RAID nebo v rámci forenzního vyšetřování je třeba obsah RAID rekonstruovat z jednotlivých disků nebo spíše z obrazů disků. Vzhledem k rozmanitosti řadičů RAID a různým možnostem implementace a konfigurace nejsou často známy různé parametry, které jsou pro rekonstrukci nezbytné. To může být způsobeno tím, že původní konfigurace prostě nebyla zdokumentována, nebo v případě forenzního šetření nemusí správce spolupracovat a není ochoten konfiguraci prozradit. Použití původního systému RAID v takových případech také nepřipadá v úvahu, protože původní důkazy by neměly být měněny. Představujeme nový přístup k automatickému zjišťování všech parametrů pro opětovné sestavení logického svazku RAID na základě měření entropie na úrovni bloků a obecné heuristiky. Poskytujeme také výkonnostně optimalizovanou open source implementaci našeho přístupu, která je schopna také dodatečně sestavit celý logický svazek RAID a dále obnovit jednotlivé chybějící disky pomocí informací o redundanci, které jsou přítomny v RAID-5.
Redundantní pole nezávislých disků RAID jsou dobrým způsobem, jak do jisté míry zabránit ztrátě dat v případě hardwarových závad na pevných discích a zároveň zvýšit výkon I/O. Vzhledem k zavedení další abstrakční vrstvy mezi pevnými disky a operačním systémem je však obtížnější rekonstruovat data souborového systému ze sady disků v případě, že nelze použít řadič RAID, protože data jsou distribuována mezi disky. Vzhledem k rozmanitosti dostupných hardwarových a softwarových řadičů RAID a různým možnostem implementace a konfigurace může být typ RAID, stejně jako další důležité informace, jako je velikost stripu a mapa stripu, neznámý. Obvykle je třeba určit všechny tyto parametry, aby bylo možné svazek RAID správně sestavit. Pokud některé z parametrů nejsou známy, musí nezpracovaný obsah disku ručně prozkoumat specializovaní analytici, aby určili správné parametry, což dnes činí z opětovného sestavení svazku RAID složitý a nákladný úkol.
Motivace k práci
Ve forenzní výpočetní analýze, jinak nazývané digitální forenzní analýza, je klíčová schopnost přistupovat k datům na dříve zabavených a zazálohovaných pevných discích. Tato schopnost je nezbytná pro mnohá vyšetřování, přičemž zvláštní důraz je kladen na rekonstrukci RAID polí, které jsou často používány v serverových prostředích pro zajištění datové bezpečnosti v případě selhání.
Aby mohl odborníci pověření forenzním vyšetřováním shromažďovat důkazy, musí být schopni rekonstruovat RAID pole z obrazů jednotlivých disků. To je nutné, protože původní RAID systém nelze využít, aby se předešlo možné změně důkazů. Komplikací bývá fakt, že často nejsou známy odpovídající parametry. To může být dáno tím, že původní konfigurace nebyla zdokumentována po instalaci, nebo protože administrátor či vlastník může být neochotný tuto konfiguraci sdělit.
Takové situace se stávají v současných vyšetřováních pravidelnou realitou, a proto je důležité mít k dispozici forenzní nástroje umožňující automatizovanou rekonstrukci RAID polí. Ačkoliv mnohé současné nástroje podporují rekonstrukci logických RAID polí z obrazů disků, vyšetřovatel musí znát všechny parametry a poskytnout je softwaru. Pokud tato konfigurace není známa, je jedinou možností ruční obnova, což je často časově náročné a drahé.
V roce 2012 Michael Perklin dokonce na konferenci DEF CON 20 navrhl, že použití vlastních parametrů RAID může sloužit jako efektivní obrana proti forenzním útokům.
Úvodní definice
Představujeme nový přístup k automatickému zjišťování všech relevantních parametrů RAID obecným způsobem pomocí měření entropie na úrovni bloků a obecných heuristik. Tyto parametry pak používáme k opětovnému sestavení původního svazku RAID. Konkrétněji používáme heuristiku založenou na vzorcích entropie souborů, které nám umožňují najít možná místa hranic stripu a potenciální body soudržnosti napříč různými pevnými disky. Tímto způsobem získáme indicie pro možné typy a parametry RAID, na jejichž základě zjistíme původní konfiguraci. Poskytujeme prototyp s otevřeným zdrojovým kódem2 , který je schopen detekovat následující parametry RAID 0, RAID 1 a RAID 5:
1. Typ RAID
2. Velikost stripu
3. Mapa stripů a pořadí disků
Náš prototyp je také schopen automaticky rekonstruovat jeden chybějící pevný disk v případě systému RAID 5 pomocí paritních informací RAID a znovu sestavit kompletní logický svazek RAID jako obraz jednoho disku. Pomocí naší implementace vyhodnocujeme výkonnost a správnost námi navržené metody.
Související práce
Heuristiky založené na entropii se již používají v některých scénářích, které se od našeho přístupu značně liší. Práce Xionga (2014) představuje přístup využívající entropii k vyhodnocení rizikových faktorů pro určité pohybové vzory získané od uživatelů mobilních zařízení. Tímto způsobem lze na základě zkoumání vzorců entropie vyvodit závěry o bezpečnosti mobilních zařízení. V zeměpisných oblastech, kde se uživatel pohybuje většinu času, je entropie velmi nízká a stejně tak i rizikový faktor. To umožňuje ověřování založené na riziku. V práci popsané ve studii Yokota (2007) je ukázáno využití entropie historií větvení řídicích toků ke kvantitativnímu popisu úrovně pravidelnosti chování programu pro zlepšení výkonu předvídání větvení.
Garfinkel a další (2010) popisují použití účelových funkcí a kryptografických hashů v kontextu forenzní analýzy malých bloků. Jejich práce má dvě různé části: Výpočty blokových hešů a analýzu hromadných dat. Hash umožňuje detekovat komprimovaná data a podobnost a používají jej ke zlepšení detekce JPEG, MPEG a komprimovaných dat pro klasifikaci forenzního obsahu disku v případě vyřezávání dat. Možným rozšířením naší práce by mohlo být použití jejich hashe navíc nebo místo entropie za účelem detekce parametrů RAID v budoucí práci.
Xiang (2011) popisuje přístup k obnově dat ze systému RAID 6. Na rozdíl od systémů RAID použitých v této práci poskytuje RAID 6 vyšší úroveň spolehlivosti díky dvěma paritním stripům. Kódy RAID 6 jako RDP chrání data až proti dvěma selháním disku (Corbett a kol., 2004). Jakmile je v běžícím systému RAID 6 zjištěno selhání jednoho disku, je zahájena obnova RAID pole bez přerušení činnosti aplikace v systému. Tento přístup se snaží snížit počet čtení potřebných k obnově, aby se minimalizoval dopad na výkon ostatních aplikací. Na rozdíl od našeho přístupu pracuje tento přístup na běžícím systému, a tedy se znalostí všech parametrů RAID.
Kiselev a další (2006) popisují přístup k automatické detekci poškozených dat v paritním systému RAID a zajištění obnovy. Pomocí dvou různých paritních dat dokáží určit, zda jsou data poškozena, a obnovit původní data.
Belhadj (2003) popisuje, jak lze upřednostnit obnovu dat v systému RAID pomocí zranitelného schématu redundance dat. Toto schéma lze určit porovnáním pravděpodobnosti ztráty dat a potenciálu jednoho nebo více selhání disku.
Práce prezentovaná Hartem (2002) popisuje automatický přístup k obnově konfigurace systému RAID po selhání systému, pokud je na tomto systému RAID spuštěn operační systém.
Algoritmus popsaný Goelem a Corbettem chrání před selháním tří disků (Goel a Corbett, 2012) pomocí tří paritních disků vzhledem ke třem obnovitelným diskům.
Dále uvádíme dva existující nástroje pro rekonstrukci RAID: RAID Reconstructor (v 4.32)3 a ReclaiMe (build 1994).4 V našem hodnocení porovnáváme oba nástroje s naším přístupem.
Přehled
Tento článek má následující strukturu: V části Předpoklady uvádíme teoretické předpoklady pro tuto práci a připomínáme specifikace různých typů RAID a jejich parametry, jakož i entropii. Detekce parametrů pomocí entropie podrobně popisuje náš přístup detekce parametrů na základě entropie. V části Vyhodnocení hodnotíme správnost našeho přístupu i jeho výkonnost a v závěru kapitoly Shrnutí.
Předpoklady
V této části připomeneme důležitá východiska pro náš přístup. Za tímto účelem nejprve nastíníme funkční princip RAID, různé typy RAID a parametry, které jsou důležité pro opětovné sestavení svazku. Poté si také stručně zopakujeme definici entropie a uvedeme několik příkladů, abychom získali první představu o tom, proč lze entropii využít k získání informací o dříve zmíněných parametrech RAID.
Typy a parametry RAID
RAID je způsob sjednocení více fyzických pevných disků do jednoho logického svazku. Hlavní myšlenkou systémů RAID je dosažení redundance, která slouží k zajištění dodatečné bezpečnosti v případě selhání pevného disku a zvýšení I/O výkonu (Chen a kol., 1994). Díky těmto výhodám jsou systémy RAID použitelné zejména v prostředí serverů. Tuto technologii však používají i soukromé osoby v malých síťových úložných řešeních (NAS). Jak bylo uvedeno výše, systémy RAID fungují transparentně vůči souborovému systému a jeví se jako jedno logické zařízení. Toho je dosaženo tím, že takzvaný řadič RAID provádí operace čtení/zápisu na pevných discích odpovídajícím způsobem s ohledem na jejich redundanci. Uvedená redundance umožňuje kompletní obnovu obsahu poškozeného pevného disku bez ztráty dat. V závislosti na použitých typech RAID, ke kterým se nyní vrátíme, se požadované postupy obnovy liší složitostí a tolerancí chyb.
Většina typů RAID používá pro zvýšení výkonu čtení a zápisu prokládání jednotlivých zařízení pevného disku. Stripingem se rozumí rozdělení datových bloků (tzv. proužků o určité velikosti) sekvenčně po zařízeních za prvé a za druhé po fyzických adresách, takže data na disku nejsou souvislá. Výsledná mapa stripů popisuje mapování logických datových bloků na jejich fyzické umístění v poli disků. Toto umístění se skládá ze zařízení, na kterém se daný datový blok nachází, a jeho adresy (offsetu) na tomto zařízení. V závislosti na řadiči RAID lze zvolit velikost proužků. Nejmenší možná velikost proužku je velikost sektoru pevného disku (512 bajtů), horní hranice však není definována.
Nejzákladnějším příkladem pro striping je RAID 0, kde mapa proužků popisuje linearizaci datových bloků po zařízeních, jak je znázorněno na obr. 1. Protože data lze zapisovat a číst paralelně, zrychluje se výkon I/O, v ideálním případě faktorem rovným počtu zařízení. Jakékoli úplné selhání pevného disku však vede k neobnovitelným a nesouvislým datům, a tedy k úplné ztrátě dat. Mapa proužků se skládá pouze z pořadí disků.
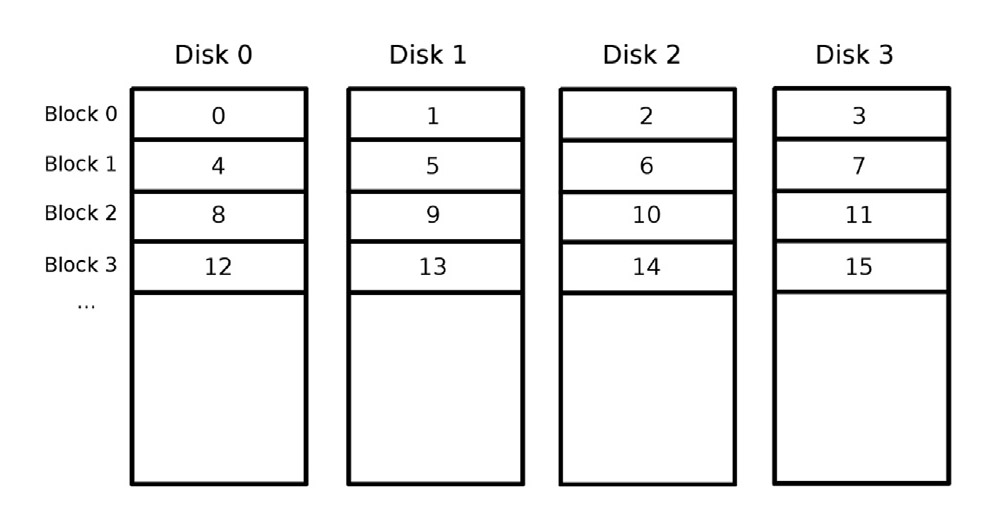
Obr. 1. Příklad rozložení datových bloků systému RAID 0 se čtyřmi disky.
Zatímco RAID 0 poskytuje prokládání a žádnou redundanci, RAID 1 představuje alternativu bez prokládání, ale s redundancí, kdy je logická jednotka zrcadlena na fyzických jednotkách. Selhat může libovolný počet pevných disků, pokud jeden zůstane nepoškozený, a obnova je triviální. Protože nedochází k prokládání, dochází k nárůstu výkonu čtením dat, ale k úzkému hrdlu, které je vynuceno zápisem na nejpomalejší zapisovací zařízení. RAID 1 ponechává pro n stejně velkých pevných disků k dispozici pouze 1/n akumulovaného místa v systému.
Všechny ostatní typy RAID poskytují redundanci prostřednictvím paritních bitů, které jsou obvykle realizovány bitovým XOR. Přístup uvedený v této práci neposkytuje podporu pro typy RAID-2 až RAID-4, které byly nahrazeny typem RAID 5, a proto se v praxi používají jen zřídka.
Spolu s RAID 0 a RAID 1 je RAID 5 nejčastěji používaným typem RAID. Kombinuje redundanci prostřednictvím parity a výkon prostřednictvím prokládání, proto jsou vyžadovány minimálně tři pevné disky. Existují různé typy parity a rozložení datových bloků, jak podrobně vysvětluje Lee (1990). Obecně se výsledná mapa proužkového rozdělení opakuje po n řádcích, přičemž n je počet pevných disků. Tyto typy rozložení jsou znázorněny pro 4 disky v tabulce 1. Existují dvě vlastnosti, každá se dvěma možnými stavy, a to {levý, pravý} a {symetrický, asymetrický}. Levostranné distribuce přesouvají své paritní bloky z posledního disku na první, zatímco pravostranné je uspořádávají způsobem od prvního k poslednímu. Symetrické rozmístění se týká začátku posloupnosti dat po řádcích za paritním blokem, zatímco asymetrické rozmístění začíná každý řádek na prvním dostupném disku daného řádku (Lee, 1990).
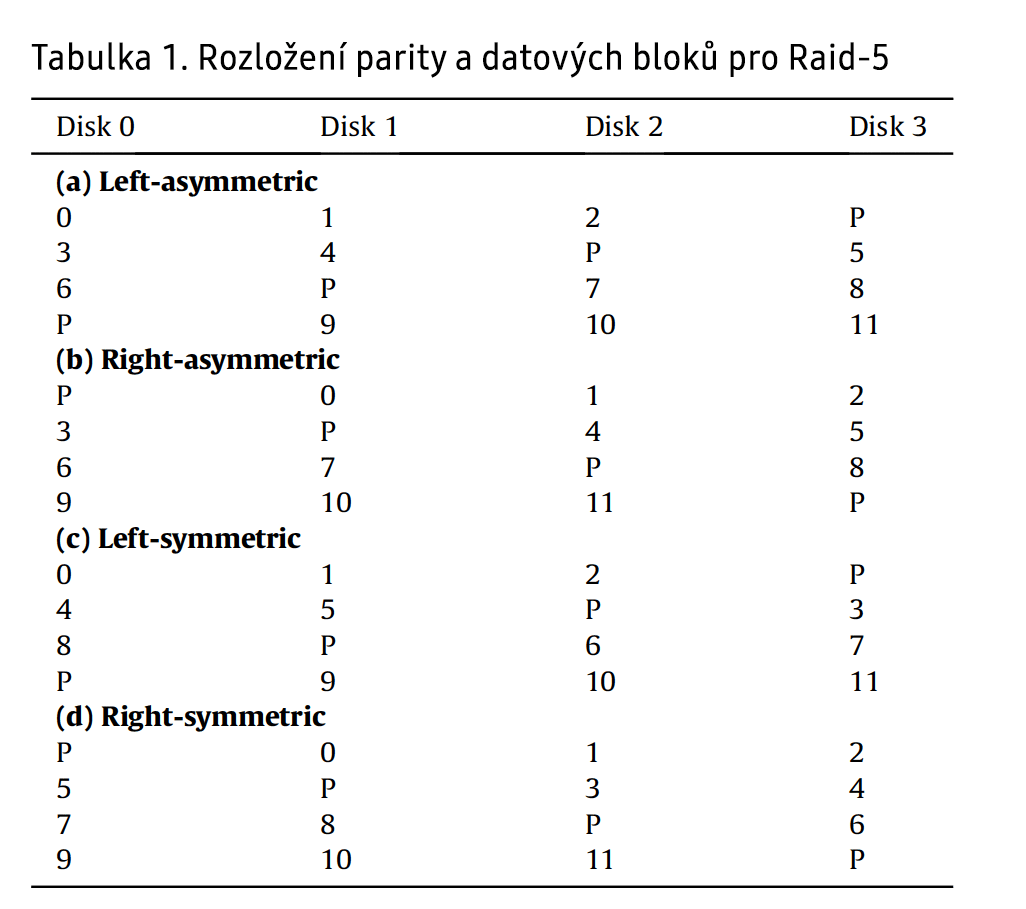
Tabulka 1. Rozložení parity a datových bloků pro RAID 5
Efektivita ukládání v RAID 5 je vyšší než v RAID 1, protože místo 1/n prostoru systému pro data, se použije pouze 1/n místa pro paritu a zbývající místo na disku je k dispozici pro ukládání dat. Pokud mají být všechna data obnovena bez ztráty informací, je tolerováno maximálně jedno selhání pevného disku. Rozložením paritních informací na více zařízení se zátěž rovnoměrně vyrovnává a výkon RAID 5 se ze stejného důvodu chová stejně jako jeho efektivita ukládání: Všechny disky kromě jednoho obsahují skutečné užitečné zatížení.
Všechny tyto parametry, tedy typ RAID, velikost stripu, mapu stripu a samozřejmě pořadí disků, je třeba určit, aby bylo možné svazek RAID znovu sestavit. Určení všech těchto parametrů vyžaduje heuristický přístup, protože testování všech možností konzistence (tj. hrubé vynucení) není proveditelné, jak jsme si ukázali v kapitole Bruteforce performance estimation. Základním konceptem heuristiky zavedené v této práci je informační entropie, kterou chceme vysvětlit dále.
Informační entropie
Entropie je v podstatě očekávaná hodnota informačního obsahu. Pro diskrétní rozdělení pravděpodobnosti (p1,p2,...) je entropie definována rovnicí (1), jak uvádějí také Devroye a Luc (1996).
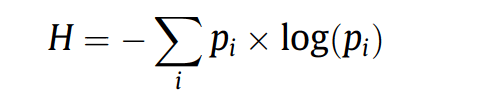
To znamená, že entropie popisuje, kolik různých informací délky n lze nalézt v dané posloupnosti dat. Nechť je například posloupností dat proud osmi po sobě jdoucích logických datových jednotek a nechť je délka informace n dvě. Každá jednotlivá datová jednotka může nabývat hodnot 0 a 1. V důsledku toho lze informaci délky dvě popsat pouze čtyřmi možnými hodnotami, a to 00, 01, 10 nebo 11. Pokud se proud skládá pouze z jednoho druhu hodnot, vyskytuje se informace pouze tohoto typu a entropie je nulová (Shannon, 2001). Největší entropie je vždy dosaženo, pokud se všechny možné hodnoty informace vyskytují stejně často. Jak ukazuje tabulka 2, nejvyšší entropie pro tento příklad je dvě. První tabulka ukazuje příkladně výsledky, pokud se vyskytuje pouze jeden typ informace. Druhá tabulka ukazuje příklad pro maximální entropii v tomto jednoduchém příkladu, kde se všechny možné hodnoty vyskytují stejně často.

Tabulka 2. Příklad vztahu mezi informačním obsahem a entropií.
Obecně platí, že nejnižší entropie je nula, zatímco nejvyšší entropie je n. Protože textové soubory mají omezený rozsah hodnot (protože se používají pouze tisknutelné znaky a například písmeno "e" je velmi časté, zatímco speciální znaky jako "#" se používají zřídka), jsou entropie bloků v celém souboru poměrně nízké (Shannon, 2001). Aby bylo dosaženo vyšších entropií, musí být obsah souboru poměrně náhodný s mnoha různými hodnotami. Například komprimované soubory mají vyšší entropii, protože se eliminuje redundance a zvyšuje se náhodnost. Naopak ve zcela náhodném souboru nelze nic komprimovat (Salomon a Motta, 2010). V důsledku toho je entropie libovolného bloku komprimovaného souboru nebo souboru, který obsahuje libovolná binární data, poměrně vysoká, stejně jako entropie celého souboru.
Tuto skutečnost využíváme k detekci hranic dat, jak je vysvětleno v následující části. Tam popsané algoritmy počítají entropii s délkou informace jeden bajt. Máme tedy 28 možností, jak se jednotlivé bajty mohou lišit, přičemž nejvyšší entropie pro každý blok je log2(28)=8 přičemž velikost bloku musí být násobkem 28.
Detekce parametrů pomocí entropie
Pro rekonstrukci logického svazku RAID je třeba znát všechny dříve vysvětlené parametry systému RAID. Tyto parametry zjišťujeme v následujícím pořadí, protože na sobě částečně závisí:
1. Typ RAID
2. Velikost proužku (stripe)
3. Mapa proužků (stripe)
4. Posun dat
Všechny tyto údaje lze určit pomocí heuristiky na základě entropie obsahu disku na úrovni bloku. Tyto různé heuristiky pro každý z parametrů jsou vysvětleny v daném pořadí v následujících částech.
Typ RAID pole
Jak je popsáno v části Typy a parametry RAID, datové bloky ("stripy") v RAID mohou být zrcadleny na různých discích nebo proužkovány s paritní informací nebo bez ní. Pro zjištění, který typ RAID byl původně použit, se počítají výskyty zrcadlených nebo paritních bloků a také bloků, které nelze přiřadit. Typ RAID pak lze určit podle tabulky 3 na následující straně. V této tabulce označuje RAID 5i neúplný systém RAID 5 s chybějícími disky, zatímco RAID 5c je kompletní systém.
| RAID 0 | RAID 1 | RAID 5c | RAID 5i | |
|---|---|---|---|---|
| zrcadlená | nízká | vysoká | nízká | průměrná |
| parita | nízká | nízká | vysoká | průměrná |
| nepřiřazená | vysoká | nízká | nízká | vysoká |
Tabulka 3. Přehled vztahu mezi počtem nalezených bloků s příslušnou vlastností a určeným typem RAID.
Abychom spočítali, kolik bloků je zrcadlených, obsahuje paritní informace nebo je nelze přiřadit, postupujeme následovně: Algoritmus zkoumá prvních 5 milionů nenulových bloků o velikosti 512 bajtů (nejmenší možná velikost proužku) na každém disku. Pomocí bitového XOR algoritmus zjistí, zda je blok zrcadlen na jiný disk (výsledkem XOR jsou pouze 0-bajty) nebo zda byl nalezen blok s paritní informací. Na základě těchto informací lze typ RAID odvodit následujícím způsobem:
Protože RAID 1 má zrcadlené disky, XOR libovolných dvou bloků se vyhodnotí jako nula. Proto musí být většina zkoumaných bloků zrcadlená, pokud jsou všechny disky správné. RAID 5 používá pro bezpečnost při selhání paritní bloky, které se rovněž počítají pomocí operace XOR. Z tohoto důvodu se v RAID 5 počítá XOR bloku všech disků, měl by se vyhodnotit jako nulový. Tímto způsobem algoritmus najde mnoho paritních bloků v kompletním systému RAID 5.
Vzhledem k tomu, že RAID 5 lze obnovit i s jedním chybějícím diskem, musí algoritmus zjistit rozdíl mezi systémem RAID 0 a neúplným systémem RAID 5. Oba systémy RAID obsahují mnoho bloků, které nejsou zrcadlené ani nemají redundantní informace. Přesto, pokud má chybějící disk systému RAID 5 prázdné bloky, lze na zbývajícím systému nalézt zrcadlené a paritní bloky. Heuristika tento případ respektuje a očekává určitý počet nepřiřazených bloků, jak je vidět v rovnici (2), kde n označuje počet disků:
Pokud je však počet zrcadlených bloků a bloků s redundantními informacemi příliš nízký, může se jednat o náhodné výskyty. Proto by součet obou hodnot měl být zlomkem počtu nepřiřazených bloků. Tyto dvě podmínky jsou dostatečné k rozlišení neúplného systému RAID 5 od systému RAID 0.
Velikost stripu
Délka informace pro výpočet entropie bloku je zvolena jeden bajt. Vzhledem k tomu, že jeden bajt má 28 = 256 možných hodnot, musí být velikost bloku alespoň 256 bajtů. Pokud byla zvolena délka dva bajty, musí být bloky pro určení velikosti proužku minimálně 512bajtové. To je již nejmenší možná velikost proužku, a proto ji nemůžeme dále zvětšit, aniž bychom ztratili kompatibilitu s touto velikostí proužku. Snižovat délku na méně než jeden bajt nemá smysl, protože jeden bajt je obvykle nejmenší používaná datová jednotka. Jediné dvě zbývající možnosti velikosti bloku, které lze v našem přístupu zvolit pro výpočet entropie, jsou tedy bloky o velikosti 256 a 512 bajtů a délka informace jeden nebo dva bajty. Jako základ pro naše výpočty jsme zvolili 512bajtové bloky s délkou informace jeden bajt, protože se ukázalo, že to snižuje vliv odlehlých hodnot v entropii, a poskytuje tak nejlepší výsledky.
Jak bylo uvedeno v kapitole Předpoklady, entropie v rámci určitého souboru zůstávají přibližně stejné. Velké rozdíly v entropii po sobě jdoucích bloků tedy mohou znamenat začátek nového proužku. Příklad rozložení entropie v systému RAID 0 se soubory obrazů je uveden v tabulce 4:
| Adresa | Disk 0 | Disk 1 | Disk 2 | Disk 3 |
|---|---|---|---|---|
| … | ||||
| 888273920 | 0 | 0 | 0 | 0 |
| 888274432 | 0 | 0 | 0 | 0 |
| 888274944 | 0 | 7.50199 | 7.56131 | 7.57583 |
| 888275456 | 0 | 7.53411 | 7.54758 | 7.54145 |
| … | ||||
| 888306176 | 0 | 7.46816 | 7.43265 | 7.48876 |
| 888306688 | 0 | 7.43318 | 7.59278 | 7.60496 |
| 888307200 | 6.14066 | 7.48741 | 7.58424 | 7.49408 |
| 888307712 | 7.64113 | 7.53735 | 7.59764 | 7.46034 |
| … | ||||
| 888732672 | 7.43689 | 7.55090 | 7.52364 | 7.54029 |
| 888733184 | 7.52416 | 7.54816 | 7.57045 | 7.53455 |
| 888733696 | 7.44034 | 7.54581 | 7.46290 | 0 |
| 888734208 | 7.47576 | 7.51771 | 7.57273 | 0 |
| … | ||||
Tabulka 4. Rozložení entropie souboru o velikosti 1,75 MB na čtyřech discích při použití RAID 0.
Vysoká entropie ukazuje obsah souboru. Je obklopen prázdnými bloky. Možnou velikost proužku lze odvodit pomocí adres bloků s vysokým rozdílem entropie, tj. hranic souboru. V tomto příkladu adresa 888274944 označuje začátek proužku. Entropie na disku 1 až 3 mají předtím hodně bloků s nízkou entropií, až se hodnota náhle změní na ≈7,5, zatímco entropie na disku 0 zůstává nulová. Takový rozdíl v entropii je u po sobě zapsaného souboru neobvyklý, protože entropie by se v takovém případě neměla výrazně měnit. Je také netypický pro začátek souboru, proto jej lze interpretovat jako začátek proužku.
Konec stripu lze lokalizovat na adresu 888733184, protože na disku 3 dochází také k náhlé změně hodnoty. Toto přerušení na následující 512bajtový blok se v rámci souboru pravděpodobně nevyskytuje a na konci souboru entropie obvykle mírně klesá, než dosáhne nuly (alespoň pokud konec souboru není přesně na hranici stripu), podobně jako na začátku souboru. V důsledku toho začíná nový blok stripu na adrese 888733696, kde soubor pokračuje na discích 0 až 2. Aby se zajistilo, že silně se měnící soubor s částečně nízkou entropií neovlivní tento přístup, berou se v úvahu i okolní entropie. V případě náhlé změny entropie z velmi nízké na velmi vysokou musí hodnoty před změnou zůstat na stejně nízké úrovni, zatímco po změně musí hodnoty zůstat vyšší než určitý práh. Nejlepší prahová hodnota se může lišit v závislosti na zkoumaném případu, který je vyhodnocen a vysvětlen v části Vyhodnocení. Předložený algoritmus kontroluje šestnáct 512bajtových bloků entropií před změnou a po změně entropie. Pokud se entropie změní z vysoké na nízkou, použije se tento postup i opačně.
Pro konečný odhad možné velikosti stripu se vypočítá rozdíl mezi dvěma po sobě jdoucími adresami. Výsledek musí být násobkem možné velikosti stripu a je klasifikován pomocí operací modulo rozumných velikostí stripu. Za možnou velikost stripu se považuje největší použitelný dělitel operací modulo, kde zbytek je nula. Ta se vypočítá pro celé disky a nakonec se potenciální velikost stripu, která se vyskytla u většiny adres, považuje za původní velikost stripu. (Ve skutečnosti jsou obvykle údaje velmi jednoznačné, jak ukazujeme v našem vyhodnocení v části Vyhodnocení).
Možný offset
Vzhledem k tomu, že softwarové RAID systémy potřebují rezervovaný prostor pro svá vlastní metadata, musí být znám offset skutečného systému RAID. V případě systémů RAID vytvořených nástrojem mdadm (verze 3.2.5) je po spuštění každého zařízení uložen 4 KB superblok s podrobnostmi o konfiguraci systému RAID. V závislosti na uspořádání disku, systému RAID a typu softwarového RAID se může posun ke skutečnému systému RAID lišit.
Algoritmus pro určení velikosti stripe, který již byl popsán v části Velikost stripu, byl rozšířen o dodatečné zjišťování offsetu. Po určení velikosti stripu se vypočítá rozdíl mezi dvěma adresami, které vedly k určení velikosti stripu. Výsledek rozdílu musí být násobkem velikosti proužku. Tak lze předpokládat, že tyto adresy označují správný stripe v rámci systému RAID. Protože se tyto adresy s největší pravděpodobností nacházejí v souborových datech systému RAID, bere se nižší adresa vypočteného rozdílu jako maximální možný offset. Tento offset se pak vezme modulo s velikostí stripu a výsledek je dolní hranicí pro offsetový algoritmus. Tímto způsobem se určí maximální rozsah, ve kterém by mělo začít prokládání systému RAID.
Mezi tímto rozsahem se použije vyhledávací algoritmus pro nalezení "magických" hodnot při určitých offsetech pro různé struktury metadat souborového systému. V případě tabulky oddílů je magická hodnota 0x55aa nalezena na offsetu 0x01fe (desetinné číslo: 510). Podporovány jsou také souborové systémy jako NTFS s magickou hodnotou NTFS nebo Ext s magickým číslem 0xef53. Nejmenší možný offset, který lze zjistit pomocí těchto magických hodnot, je brán jako offset Software-RAID a je použit na všech discích.
Mapa stripů
Po určení velikosti stripu a možného offsetu je třeba pro systémy RAID 0 a RAID 5 rekonstruovat mapu stripu. K tomuto účelu využijeme skutečnost, že bloky dat v proužcích jsou zapisovány postupně na všech pevných discích. Výsledkem je, že prázdné datové bloky mohou napovědět, zda byl tento blok zapsán před nebo za jiný neprázdný blok stripu. To závisí na rozložení entropie okolních bloků. Každý proužek rozdělíme na dvě části a vypočítáme entropii pro každou část zvlášť, abychom zjistili klesající a stoupající hrany entropie v rámci proužku. Klesající hrany mohou být indikátorem konce souboru, zatímco rostoucí hrana indikuje začátek souboru.
Pokud je taková hrana nalezena, je adresa považována za zajímavou. Dále se zkoumají datové bloky těchto kandidátských adres na hranici na ostatních discích. Prázdný blok musí být zapsán před datový blok s vzestupnou hranou nebo za datový blok s klesající hranou. Tímto způsobem lze odvodit pořadí disků a především pořadí zápisu datových bloků. Jak je uvedeno v části Předpoklady pro systém RAID 0, je vyžadováno pouze pořadí disků.
V případě systému RAID 5 je třeba vzít v úvahu různé řádky mapy stripu a také určit rozložení paritních bloků, jak již bylo vysvětleno v kapitole Předpoklady. K výpočtu pozice v rámci mapy stripu se používají adresy kandidátů na hranice, jak je uvedeno v rovnici (3). Nechť n je počet pevných disků systému RAID a s je určená velikost proužku. Řádek mapy proužků "r" se pak vypočítá pomocí hraniční kandidátní adresy a následujícím způsobem:
Pro určení rozložení parity u systémů RAID 5 se zkoumají nenulové datové bloky, opět pomocí entropie. Protože se paritní bloky počítají metodou XOR, je jejich obsah obvykle náhodnější než obsah odpovídajících datových bloků (u neprázdných bloků). Nalezené paritní bloky se spočítají a přiřadí se k záznamu v mapě stripu. Pomocí rovnice (3) se vypočítá pozice v mapě stripů. Konečné rozložení paritních bloků je poměrně spolehlivé, takže je lze s jistotou nastavit. Příklady pro vázané případy možných rozložení paritních bloků jsou uvedeny ve vyhodnocení.
Popsané informace slouží k určení typu systému RAID 5. Jak je uvedeno v části Předpoklady, systém RAID 5 může být {levý, pravý} a {asymetrický, symetrický}. Pro tento účel poskytuje výchozí situaci rozložení parity. Poté lze typ systému RAID 5 určit pomocí následujícího zjednodušeného algoritmu:
curNum = -1
for (i=1; i < #rows) {
for (j = 0; j < #cols) {
if (stripeMap[i] [j] .isParity()) {
if (stripeMap[i-1] [j] .blockNum. isValid()) {
if (curNum == -1) {
curNum = stripeMap[i-l][j].blockNum
} else {
if (stripeMap[i-1][j].blockNum > curNum)
{
asymm_right = true
} else if (stripeMap[i-1] [j] .blockNum <
curNum) {
asymm_left = true
} else {
if (stripeMap[i-1][j].blockNum == 0) {
symm_right = true
} else {
symm_left = true
} } } } } } }V každém řádku mapy proužků je umístěn pevný disk s paritním blokem. Poté se zkontroluje dříve zapsaný blok dat na tomto pevném disku. V každém řádku musí být tento datový blok prvním nebo posledním zapsaným blokem pro pravostranný symetrický, resp. levostranný symetrický systém RAID 5. V asymetrickém případě musí být tyto datové bloky seřazeny vzestupně nebo sestupně - podle řádků v mapě stripů - pro označení pravého nebo levého systému RAID 5. Tyto vzory lze také vidět v tabulce 1 na straně 3 v části Předpoklady.
Hodnocení
V této části je náš přístup vyhodnocen pomocí naší implementace. Pro různé druhy typů RAID a pro různé datové sady byla testována stabilita, výkonnost a správnost.
Datová sada
Abychom mohli náš přístup vyhodnotit na realistické sadě dat, použili jsme hardwarový řadič RAID Adaptec®6405 Family Controller. Abychom pokryli různé typy RAID a také různé velikosti stripu a souborové systémy, kombinovali jsme je navzájem. Kromě toho jsme pro každý z těchto případů vytvořili dvě varianty s nejproblematičtějšími hraničními případy týkajícími se měření entropie: Disky s daty s nízkou entropií (textové soubory) a s daty s vysokou entropií (komprimované obrazové soubory, tj. JPEG).
- Typy RAID: RAID 0, RAID 5 (jak již bylo řečeno, RAID 1 je triviální).
- Velikost stripů: 16 KB, 64 KB, 256 KB, 1024 KB.
- Souborový systém: Souborový systém: Ext4 a NTFS
- Data: Soubory: Obrázkové soubory a procházený text a obrázkové soubory.
Takto jsme získali
systémy RAID se 4 disky, každý o velikosti 10 GB, a navíc tři 500 GB systémové disky Ubuntu Linux pro RAID 0 a pro RAID 5, což tvoří 38 systémů RAID s celkem 152 obrazy pevných disků, na kterých jsme hodnotili námi navrženou metodu. Dále bylo vytvořeno několik systémů RAID 5 pomocí nástroje mdadm, aby bylo možné vyhodnotit správnost detekce posunu pro softwarové RAIDy.
Abychom získali soubor dat, který nejenže pokrývá potenciálně nejproblematičtější případy, ale také se co nejvíce blíží reálným obrazům, byly dále použity obrazy s instalací Ubuntu Linux, aby bylo zajištěno, že data byla na obraze také přesouvána, alokována a dealokována.
Určení optimálních prahových hodnot
Jak již bylo zmíněno v části Detekce parametrů pomocí entropie, pro zjištění velikosti stripu je třeba stanovit určité prahové hodnoty pro rozdíly v entropii. Pro různé datové sady a souborové systémy se optimální prahové hodnoty liší. Přesto existuje více kombinací prahů pro každou datovou sadu, se kterou bylo obnovení úspěšné. Výpočtem průniků těchto kombinací jsme určili univerzální prahovou hodnotu. Případně by bylo možné stanovit prahové hodnoty pro konkrétní případ, pokud existuje dostatek předběžných znalostí o vlastnostech souborů a souborového systému, ale naše vyhodnocení ukazuje, že to není nutné.
Na obr. 2 je uvedeno několik vybraných příkladů míry shody pro správnou velikost stripu (osa y) v závislosti na zvolených rozdílných horních a dolních prahových hodnotách (osa x a z), pro detekci velikosti stripu. Na dílčím obrázku 2a je vidět, že kombinace systému NTFS a velkých obrazových souborů je značně nezávislá na zvolených prahových hodnotách a je velmi robustní. Vzhledem k tomu, že se vyskytují pouze vysoké entropie z obrázkových souborů (≈7.9) a velmi nízké entropie z prázdných bloků (≈0.0) - což jsou okrajové případy - zvolené prahové hodnoty nezpůsobují rozdílné výsledky. Další dvě rozdělení, která jsou znázorněna na obr. 2b a c, vykazují rozdílné výsledky. Vrcholu obou grafů je dosaženo při vysoké vzdálenosti mezi oběma prahy. Mnoho různých typů souborů, s nimiž se příkladně setkáváme v operačních systémech, vede k velmi rozdílným entropiím. Proto je obtížnější rozlišit po sobě jdoucí bloky proužků. V důsledku toho je třeba volit prahy pečlivěji, aby nedošlo k chybné interpretaci změny entropie v rámci souboru jako začátku nového stripového bloku. Nakonec se v závislosti na těchto výsledcích odhadnou nejlepší dolní a horní prahové hodnoty. Pro všechny případy souboru dat popsaného v části Datový soubor jsou nejvhodnější prahy 0,3 pro dolní práh a 7,3 pro horní práh tak, že v průměru lze pomocí těchto prahů dosáhnout nejlepších výsledků.
Obr. 2 a+b+c. Distribuce závislosti algoritmu na velikosti stripu při použití určitých kombinací prahových hodnot entropie. Čím vyšší je hodnota na ose z, tím vyšší je spolehlivost. Ostatní osy znázorňují testované entropie pro horní a dolní prahy.
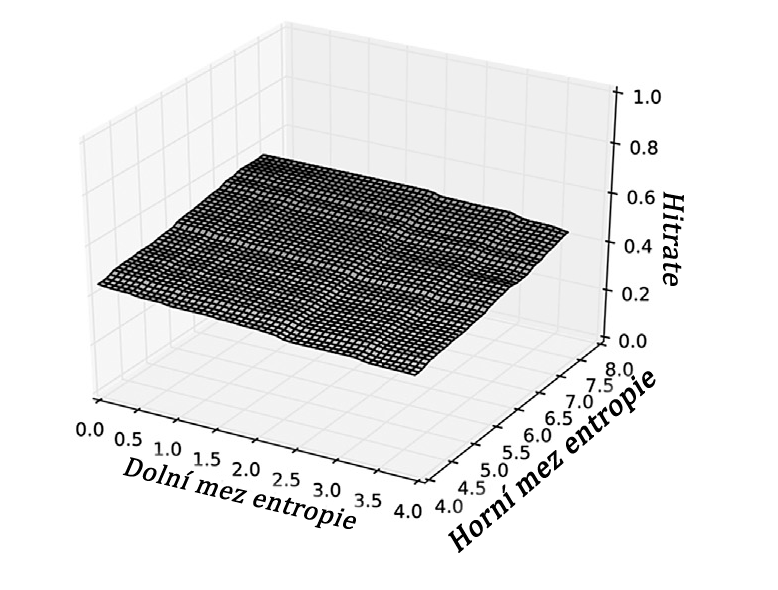
(a) Distribuce pro systém NTFS zaplněný soubory s obrázky při použití pole RAID 5 s velikostí stripu 256 KB
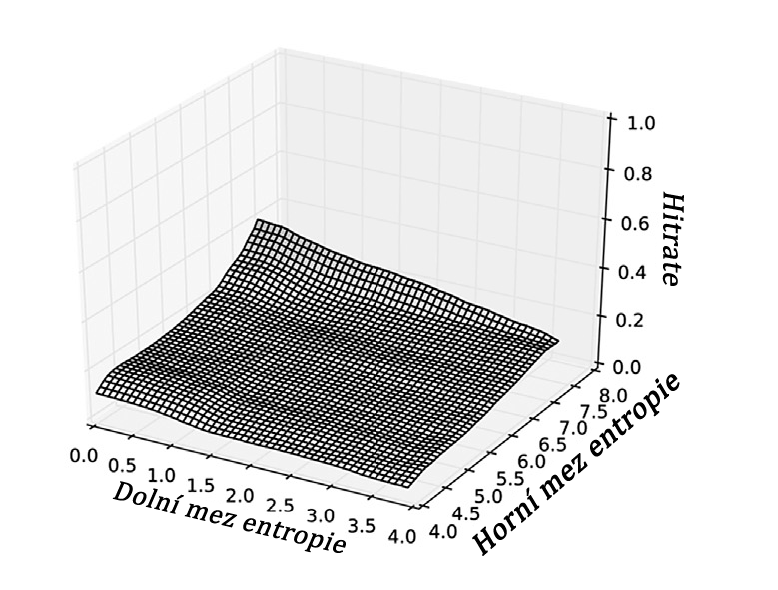
(b) Distribuce pro operační systém Linux využívající RAID 5 s velikostí stripu 512 KB.
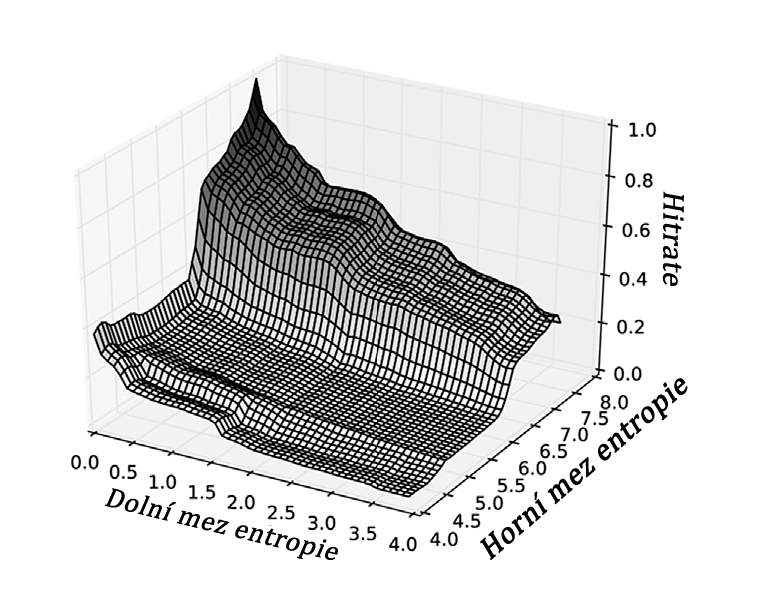
(c) Distribuce pro souborový systém Ext4 naplněný mnoha malými soubory pomocí RAID 0 s velikostí stripu 1024 kB.
Správnost
Jak je popsáno v části Detekce parametrů pomocí entropie, k výpočtu potenciálních velikostí jednotlivých pruhů se používají adresy kandidátů na hranice. Na obr. 3 jsou znázorněna rozložení potenciálních velikostí stripů s použitím dříve stanovených prahových hodnot, přičemž osa y představuje pravděpodobnost velikostí pruhů. U všech grafů je výsledek zřejmý a lze určit správnou velikost stripu.
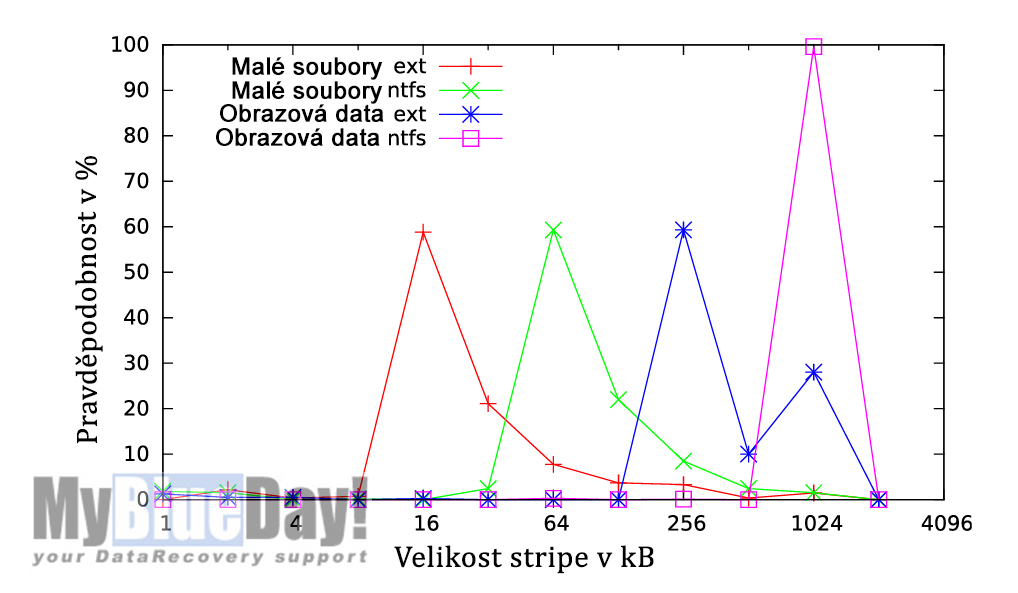
Obr. 3. Rozdělení pravděpodobnosti potenciálních velikostí stripu pro určité případy. Vrcholy označují velikost stripů pro konkrétní případ.
Jak je uvedeno v části Detekce parametrů pomocí entropie, paritní bloky proužku by měly mít největší entropii v rámci řádku. Tento předpoklad jsme ověřili pomocí naší sady dat a výsledků uvedených v tabulce 5 na následující straně, která zobrazuje nalezená rozložení parity pro různé mapy proužků RAID 5. Tabulka 5a ukazuje jednoznačné rozložení parity, protože velké obrazové soubory mají rovnoměrné hodnoty entropie. Na rozdíl od tabulky 5b mohou být obrazové soubory větší než velikost stripu, což činí velké změny entropie nepravděpodobnými. Velké množství malých souborů může způsobit velké změny entropie mezi bloky stripu. I když v tomto případě, který je uveden v tabulce 5b, není mapa parity tak zřejmá, přesto ji lze přesně odvodit.
Tabulka 5. Rozložení parity mapy stripů pro různá nastavení RAID 5.
| Disk 0 | Disk 1 | Disk 2 | Disk 3 |
|---|---|---|---|
| (a) Rozdělení parity pro obrazové soubory | |||
| 0 | 4958 | 0 | 0 |
| 0 | 0 | 5002 | 0 |
| 0 | 0 | 0 | 4911 |
| 4922 | 0 | 0 | 0 |
| (b) Rozdělení parity pro malé soubory | |||
| 485 | 480 | 497 | 3805 |
| 469 | 512 | 3808 | 478 |
| 499 | 3785 | 490 | 498 |
| 3800 | 518 | 442 | 510 |
V případě systému RAID 0 nelze určit rozložení parity, protože tento typ RAID nepodporuje paritní informace. Výpočet výsledné mapy stripů závisí pouze na pořadí disků.
Naši implementaci jsme aplikovali na všechny systémy RAID z naší dříve popsané sady dat a nechali ji rekonstruovat logický svazek RAID. Správnost opětovného sestavení jsme ověřili připojením výsledných obrazů a analýzou tabulek oddílů i metadat souborového systému.
Ve všech případech ze souboru dat kromě jednoho dokázal náš nástroj úspěšně automaticky zjistit všechny potřebné parametry a znovu sestavit původní svazek RAID. Jediným neobnovitelným případem je systém RAID 0 se souborovým systémem Ext4, množstvím malých souborů a velkou velikostí stripu. Tato kombinace velké velikosti stripu s velmi malými soubory v RAID 0, kde nejsou přítomny žádné paritní informace, je problematickým případem, protože není k dispozici dostatek informací pro úspěšné automatické obnovení správného pořadí disků. V takovém případě musí subjekt provádějící šetření poskytnout původní pořadí disků, pokud je známo, nebo musí vyzkoušet různá pořadí, což je
a pro mnoho skutečných případů se 3 disky (maximálně 6 pokusů) nebo možná dokonce se 4 disky (24 pokusů) ještě může být rozumné. Přesto může algoritmus již nějakou část pořadí najít.
Odhad výkonu metodou "bruteforce"
Ve ojedinělých případech, kdy byla použita vlastní konfigurace, u níž nejsou známy žádné parametry, a automatická detekce selže, zbývá jediná alternativa, a to zjistit parametry hrubou silou. V nejhorším případě by bylo nutné otestovat každou možnou kombinaci parametrů. Pro každou vyzkoušenou kombinaci je třeba obnovit alespoň část obrazu, aby bylo možné provést testy konzistence a zjistit, zda byly zvoleny správné parametry. V závislosti na datech na obraze a použitém souborovém systému to není triviální úkol, ale chceme alespoň naznačit. Jedním z možných přístupů by bylo zjistit použitý souborový systém, pak odhadnout, ve které části celého obrazu jsou obvykle uložena metadata souborového systému, aby bylo možné tuto část znovu sestavit (při respektování offsetů) a pak se pokusit interpretovat struktury souborového systému a získat například výpis kořenového adresáře. I když se to podaří, nezaručuje to, že bylo vše sestaveno správně, protože všechny informace se mohou vejít do jediného nebo jen několika po sobě jdoucích pruhů, takže k úspěšné kontrole stačí částečně správná rekonstrukce. Takový test by však mohl odhalit možné kandidáty správného odhadu konfigurace, které lze následně využít k úplnému sestavení logického svazku za předpokladu, že konfigurace je správná, a ručně mezi těmito kandidáty vyhledat správný obraz.
Abychom si udělali představu o úsilí, které je třeba v takovém případě vynaložit, chceme na příkladu naší sady dat ukázat, jak vypočítat počet možných konfigurací. Nechť tedy s označuje možné hodnoty velikosti stripu, r je počet možných typů RAID kromě RAID 1 a m je počet možných konfigurací mapy stripů. Protože RAID 1 má pouze jednu konfiguraci, je třeba tento případ počítat nahoře. Pak N je výsledný počet konfigurací, které je třeba otestovat:
Zde může s nabývat deseti různých hodnot, protože velikost stripu lze nastavit od 1 KB do 1024 KB. Typ RAID r může být RAID 0 a RAID 5, což jsou dvě možnosti (protože RAID 1 je triviální a nepotřebuje rekonstrukci, pokud je zadán alespoň jeden obraz). Konfigurace mapy stripů obecně závisí na rozložení bloků v jedné řadě na discích, což činí možnosti pro P, což je počet zařízení. Vezmeme-li v úvahu čtyři různé konfigurace stripe mapy, jak jsou popsány v oddíle 2, a například čtyři zařízení, jak je tomu v naší hodnotící datové sadě, m by se vypočítalo jako . Nakonec bychom tedy dostali možných konfigurací pro naše ukázkové systémy RAID.
Srovnání s jinými nástroji pro rekonstrukci RAID
Nyní bychom rádi provedli krátké srovnání naší implementace se dvěma již zmíněnými existujícími nástroji a to RAID Reconstructor a ReclaiMe.
RAID Reconstructor nedokáže automaticky detekovat typy RAID, ale je schopen najít počáteční sektor. K tomuto účelu používá k analýze pole RAID diferenciální entropii. Přesto je entropie většinou příliš nízká na určení jakéhokoli parametru a nástroj se přeruší se zprávou "Tento výsledek není významný". Nástroj RAID Reconstructor bohužel selhává u všech snímků v naší dříve popsané sadě testovacích dat.
ReclaiMe postrádá schopnost automatické detekce typů RAID, ale oproti našemu nástroji navíc podporuje detekci parametrů pro vnořená pole RAID. ReclaiMe si poradí s většinou obrazů v naší datové sadě, ale v některých případech není schopen najít potřebné parametry, detekuje špatné parametry, a proto selže, nebo skončí s hlášením "blank disk error" (nástroj předpokládá, že obrazy disků jsou prázdné, což není pravda). Podrobné výsledky hodnocení programu ReclaiMe pro naši sadu dat jsou uvedeny v tabulce 6 pro obrazy RAID 0, z nichž je 52,6 % rekonstruováno správně, a v tabulce 7 pro obrazy RAID 5, z nichž je správných pouze 15,8 %. Zejména u systémů RAID s velkými proužky (např. 1024 KB) lze obnovu provést jen stěží. V případech, pro které detekce parametrů funguje, trvá u 40 GB systémů RAID na naší dříve popsané testovací hardwarové sestavě přibližně 23 min ve srovnání s 4,5-8,5 min, které k detekci potřebuje náš nástroj. Náš nástroj tedy poskytuje lepší výsledky (správně detekuje všechny testovací případy kromě jednoho) a je dokonce mnohem rychlejší než ReclaiMe.
Tabulka 6. Výsledky hodnocení ReclaiMe pro diskové pole v konfigurace RAID 0
| FS | Stripe S. | Obsah | Kor. | Nekor. | Nenalezeni | Chyba |
|---|---|---|---|---|---|---|
| Ext | 512 | Ubuntu | x | |||
| Ext | 128 | Ubuntu | x | |||
| Ext | 32 | Ubuntu | x | |||
| NTFS | 16 | Pictures | x | |||
| NTFS | 64 | Pictures | x | |||
| NTFS | 256 | Pictures | x | |||
| NTFS | 1024 | Pictures | x | |||
| Ext | 16 | Pictures | x | |||
| Ext | 64 | Pictures | x | |||
| Ext | 256 | Pictures | x | |||
| Ext | 1024 | Pictures | x | |||
| NTFS | 16 | Crawl | x | |||
| NTFS | 64 | Crawl | x | |||
| NTFS | 256 | Crawl | x | |||
| NTFS | 1024 | Crawl | x | |||
| Ext | 16 | Crawl | x | |||
| Ext | 64 | Crawl | x | |||
| Ext | 256 | Crawl | x | |||
| Ext | 1024 | Crawl | x | |||
| Sum | 10 | 0 | 6 | 3 | ||
| % | 52.6 | 0 | 31.6 | 15.8 | ||
Tučný text jsou součty shora uvedených hodnot.
Tabulka 7. Výsledky hodnocení aplikace ReclaiMe pro pole v konfiguraci RAID 5.
| FS | Stripe S. | Obsah | Kor. | Nekore. | Nenalezeno | Chyba |
|---|---|---|---|---|---|---|
| Ext | 512 | Ubuntu | x | |||
| Ext | 128 | Ubuntu | x | |||
| Ext | 32 | Ubuntu | x | |||
| NTFS | 16 | Pictures | x | |||
| NTFS | 64 | Pictures | x | |||
| NTFS | 256 | Pictures | x | |||
| NTFS | 1024 | Pictures | x | |||
| Ext | 16 | Pictures | x | |||
| Ext | 64 | Pictures | x | |||
| Ext | 256 | Pictures | x | |||
| Ext | 1024 | Pictures | x | |||
| NTFS | 16 | Crawl | x | |||
| NTFS | 64 | Crawl | x | |||
| NTFS | 256 | Crawl | x | |||
| NTFS | 1024 | Crawl | x | |||
| Ext | 16 | Crawl | x | |||
| Ext | 64 | Crawl | x | |||
| Ext | 256 | Crawl | x | |||
| Ext | 1024 | Crawl | x | |||
| Sum | 3 | 8 | 5 | 3 | ||
| % | 15.8 | 42.1 | 26.3 | 15.8 | ||
Tučný text jsou součty shora uvedených hodnot.
Souhrn
V této práci jsme představili nový přístup k automatickému zjišťování relevantních parametrů RAID obecným způsobem pomocí entropie na úrovni bloků pro opětovné sestavení původního svazku RAID. Pomocí entropie je prezentovaný algoritmus schopen najít možná místa hranic stripů a potenciální body soudržnosti napříč různými pevnými disky a odhadnout tak velikost stripu a mapu stripu systému RAID. Nabízíme hotovou implementaci představeného algoritmu s vysokým výkonem pro přiměřeně velké systémy RAID, která je schopna pracovat s RAID 0, RAID 1 a RAID 5.
Závěr a omezení
Došli jsme k závěru, že základní princip opětovného sestavení systémů RAID pomocí heuristiky založené na entropii lze použít s vhodnými prahovými hodnotami a parametry. Naše testy ukázaly, že ve většině případů bylo možné kompletní opětovné sestavení systému RAID včetně automatické detekce všech parametrů RAID provést v přiměřeném čase. Náš software by měl být rozšiřitelný tak, aby podporoval systémy RAID 3, RAID 4 a RAID 6 vzhledem k jejich koncepční podobnosti s RAID 5. Vzhledem k převaze společných vzorů rozložení parity systémů RAID 5 je algoritmus schopen sestavit systém RAID bez ohledu na pořadí pevných disků.
Nedostatek paritních informací v systémech RAID 0 však ztěžuje určení pořadí pevných disků. Nicméně typy vyskytujících se souborů mají velký význam pro přesnost zjištění parametrů. Nejpřínosnější jsou velké obrazové soubory, zatímco malé soubory jakéhokoli typu poskytují prostřednictvím analýzy entropie méně informací.
V případě, že by prázdné místo na discích nebylo vyplněno nulou, ale inicializováno náhodnými daty (která mají obvykle vysokou entropii), náš přístup by nefungoval. Naštěstí všechny současné systémy RAID, které známe, inicializují disky pouze nulami. Stejně tak v případě šifrovaných souborových systémů v RAID a plně šifrovaných obrazů, které mají (jednoznačně) vysokou entropii v celém obraze, nelze pomocí našeho přístupu zjistit správnou parametrizaci. V takových případech náš přístup nepomůže při rekonstrukci svazku RAID, ovšem v takových případech musíme tak jako tak čelit mnohem těžšímu problému prolomení šifrování.
Výhled a budoucí práce
Jak již bylo zmíněno, rozšíření uvedeného nástroje pro systémy RAID 3, RAID 4 a RAID 6 je spolu s vnořenými typy RAID dalším reálným cílem vývoje (Wu a Chin, 2022).
Aby bylo možné vyřešit problém pořadí pevných disků pro RAID 0, je třeba permutovat určité množství pevných disků, aby se vytvořilo potenciální pořadí disků, ze kterých lze generovat obrazy. Aby bylo možné zvládnout faktoriální množství práce v rozumném čase, mohl by být náš nástroj snadno rozšířen tak, aby bylo možné rozdělit pracovní zátěž v clusteru.
V neposlední řadě bychom se mohli pokusit dále zlepšit detekci parametrů přidáním dalších blokových měr, jako je například hash použitý Garfinkelem a dalšími (2010), jak je uvedeno v části Související práce.