Jak probíhá záchrana dat z diskového pole RAID 0 2 x 22TB
Diskové pole RAID 0 nacházelo masivní uplatnění v době, kdy vznikla jistá disproporce mezi nabízenou maximální kapacitou pevných disků, a nastupujícím trendem generovaní velkoobjemových, zpravidla audiovizuálních dat. Tvůrci obsahu, pracující např. v postprocesingu využívali možnosti spojení dvou fyzických pevných disků do jednoho svazku s výslednou dvojnásobnou kapacitou a s cca 30% navýšením výkonu. V době, kdy byl disk o kapacitě 500GB technologickým maximem, měl tento typ pole i za cenu zásadně zvýšeného rizika ztráty dat opodstatnění.
Do naší laboratoře v MyBlueDay bylo zákazníkem doručeno nefunkční diskové pole RAID. Zákazník nám popisuje situaci, kdy se RAID pole stávalo postupně nedostupné s tím, že použitý řadič hlásil delší dobu problémy s konzistencí souborového systému. Nyní dle vyjádření klienta není jeden z členů pole detekovaný ani v administraci RAIDu, ani v BIOSu použitého serveru.
Specifikace diskového pole byla následující: RAID 0 v zařízení NAS Synology. Použité pevné disky: 2x Western Digital WD221KFGX o kapacitě 22TB (celková kapacita pole 44TB). Použitý souborový systém: nejasný, předpoklad EXT4 nebo BTFRS. Šifrování: nejasné.
Potřebuji obnovit data na RAID
Diagnostika diskového pole RAID
Prvním krokem při analýze aktuálního stavu diskového pole je exaktní diagnostika každého z členů pole. Vzhledem k typu pole je nezbytné určit, zda je každý z disků v bezvadném stavu, nebo zda vykazuje abnormality. Vzhledem k tomu, že uživatel informuje o problému s detekcí jednoho disku, je předpoklad na hardwarové pozadí celého problému zcela relevantní.
K prověření stavu disků bylo použito karty PC-3000. Vzhledem k nestandardnímu modelu disku, který byl v poli použitý, byl i proces diagnostiky poměrně náročný. A z jakého důvodu? Pevný disk modelové řady WD221KFGX patří aktuálně mezi absolutně hi-end mechanické pevné disky, který disponuje řadou velmi pokročilých technologií, které však, v případě selhání, významně komplikují snahy o záchranu dat. V první řadě se jedná o extrémní mechanickou konstrukci. Tento disk disponuje 10(!) datovými plotnami, jejichž obsah čte celkem 20(!) čtecích - zapisovacích hlav. Aby bylo možné tuto konstrukci vtěsnat do standardního těla 3.5" pevného disku, jsou veškeré rozteče naprosto minimalizovány. Aby se zabránilo vzniku nežádoucího třeni a následnému generování tepla, je disk plněn héliem, které má nižší hustotu než vzduch.
Ani tato extrémní interní konstrukce by však nezaručila schopnost uložit takový objem dat. Řešením, jak u disku využívajícího standardní technologii zápisu CMR (běžné, nepřekrývající se stopy) je zmenšení nejmenší oblasti, do které se ukládají informace. Běžné čtecí a zapisovací hlavy využívající k uložení dat magnetických vlastností použitého materiálu jsou již na hranicích svých možností. Při pokusech o zmenšení oblasti pro uložení dat docházelo k významné chybovosti a nestabilitě zápisu a následného čtení uloženého obsahu. Řešení přineslo použití nových čtecích hlav disku, využívajících technologie ePMR. Zjednodušeně, před uložením dat r/w hlava krátce a intenzivně zahřeje povrch datové plotny, čímž změní vlastnosti kovového materiálu a umožní uložit data do fyzicky menší oblasti stabilně a konzistentně. A to stále není všechno. Aby se dosáhlo skutečně maximálních možných přenosových rychlostí, je disk osazen celkem 64GB velmi rychlé NAND paměti (nad rámec 512MB vyrovnávací cache paměti), která dokáže uchovávat právě zpracovávaná data a tím výkon tohoto mechanického pevného disku posunout skutečně velmi vysoko. Do jisté míry se jedná o reinkarnaci technologie SSHD, používané u harddisků před nástupem SSD.
U novějších verzí tohoto typu disku, např o kapacitě 28TB výrobce již použil tzv. "šindelový zápis" SMR, který funguje velmi zjednodušeně na principu vzájemného překrývání jednotlivých stop, do kterých dochází k ukládání dat. Tím je dosaženo vyšší hustoty zápisu dat na plošnou jednotku. Nevýhodou je samo sebou logicky náročnější způsob zápisu dat na takový disk a s tím související nižší výkon při dlouhodobém kontinuálním zápisu. Proto obecně platí, že SMR disky nejsou ideální volbou do síťových úložišť NAS, nebo serverů.
Výše uvedeným popisem jsme chtěli na konkrétních příkladech použitých technologií dokumentovat, že tyto typy disků jsou extrémně složitá zařízení, kde existuje poměrně mnoho variant selhání, která budou mít na první pohled obdobné symptomy. Proto se diagnostika takového zařízení neobejde bez zcela nadstandardního přístupu s nadstandardními nástroji. Je nutné eliminovat jednotlivé možné varianty závady, protože jenom tak je možné zvolit správnou strategii obnovy dat.
V tomto konkrétním případě bylo měřením zjištěno, že první z disků v poli pracoval v rámci svých parametrů a nevykazoval abnormality. Problém však nastal u druhého disku. Potvrdilo se zjištění zákazníka a problematické detekci. Disk vykazoval silnou nestabilitu při kalibraci, tzn. při běžném provozu byl kontinuálně resetován. Z tohoto důvodu nebyl standardními prostředky přístupný.
Na základě komplexního měření jsme došli k závěru, že příčinou chování je silná degradace povrchu jedné datové plotny. R/W hlavy naštěstí bez abnormalit, NAND část také. Veškeré moduly firmware bez problému. Za jiných okolností, tj. u jiného typu HDD bychom nebyli zcela rádi, protože v kontextu použití v poli RAID 0, patří zrovna poškození datové plotny disku k velmi nepříjemným závadám, které snižují úspěšnost kompletní záchrany dat. U tohoto modelu disku se však jednalo o stav, který jsme považovali za "rozumný". V zásadě z opět zjednodušeně. Vzhledem ke konstrukčnímu řešení disku by byla extrakce, výměna hlav, etc. extrémně komplikovaná a prognóza eufemisticky řečeno nedobrá. Zatímco defektní povrchy datové plotny jsou nepříjemné tím, že mají vliv přímo na uložená data, tak pokud není poškození extrémního charakteru, lze provést obnovu i stávajícími technickými prostředky.
Vlastní práce na záchraně dat
Vzhledem k tomu, že diagnostika RAID pole, její výsledek a námi navřené řešení a postup bylo klientem akceptováno, pustili jsem se do práce.
Jako první jsme zahájili práce na klonování disku, který nevykazoval žádné chyby. Disk četl parádně, po pár minutách dosahoval stabilně rychlosti kolem 280 MB/s, což je na mechanický disk skvělé. S drobnými výkyvy a postupnou ztrátou rychlosti čtení a především zápisu na cílový disk nám zabralo vytvoření kompletní bezchybné image cca 30 hodin. Pro uložení binární kopie jsme využili identický 22TB disk a práce proběhla pomocí hardwarového nástroje Deepspar DiskImager. S největší pravděpodobností by bylo možné u tohoto disku použít i čistě softwarového postupu. Naší prioritou je ovšem maximální bezpečnost, proto i pro práci na "zdravém" disku využijeme pokročilého nástroje, který by v případě neočekávaného selhání zpracovávaného disku pracoval spolehlivě a nedovolil by pokračovat v případě, že by další čtení mělo vést k silné degradaci.
Simultánně probíhala práce na poškozeném disku. V tomto případě jsme již použili kartu PC-3000 + Data Extractor. Po vytvoření nové úlohy a primárním nastavení jsme spustili klonování nestabilního disku na zdravý disk o stejné nominální kapacitě 22TB (pozn. v této fázi jsme na 44TB diskové kapacity nutné pro úvodní práce).
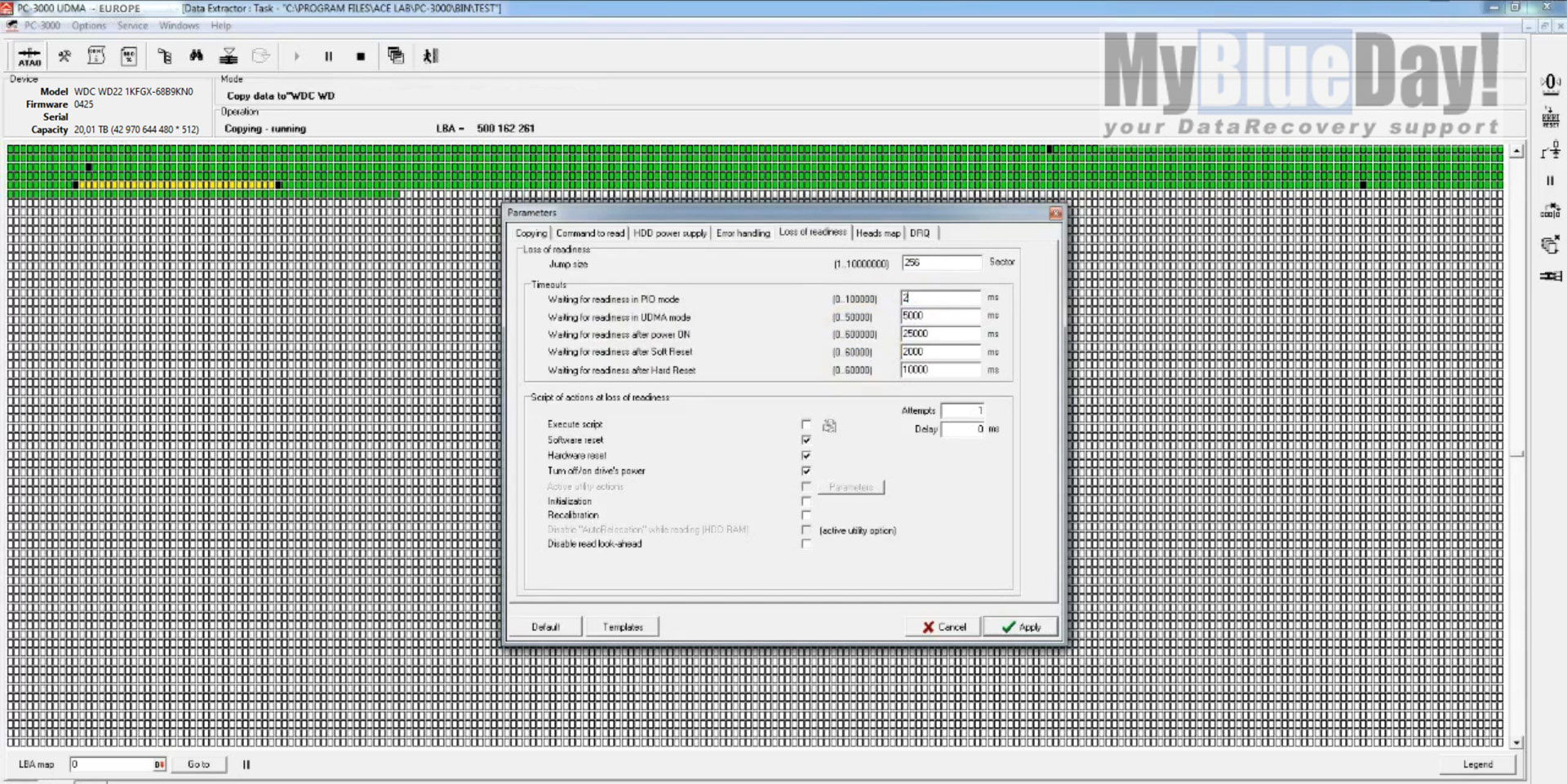
Obrázek 1.: naprosto zásadní je u tohoto typu závady správné nastavení časových prodlev čtení, tzv. timeouts.
Jak vidíte na obrázku 1, během klonování jsme narazili na oblasti, které jsou velmi obtížně čitelné. Z některých sektorů (jsou to ty černé) nelze vyčíst obsah ani mnoho násobným opakováním. Problém je, že se současným nastavením se extrémně snižuje rychlost čtení, a to tak že bychom takový poškozený disk mohli zpracovávat pár let (v praxi by ovšem při takové snaze rychle kompletně degradoval a selhal definitivně), což je nesmysl.
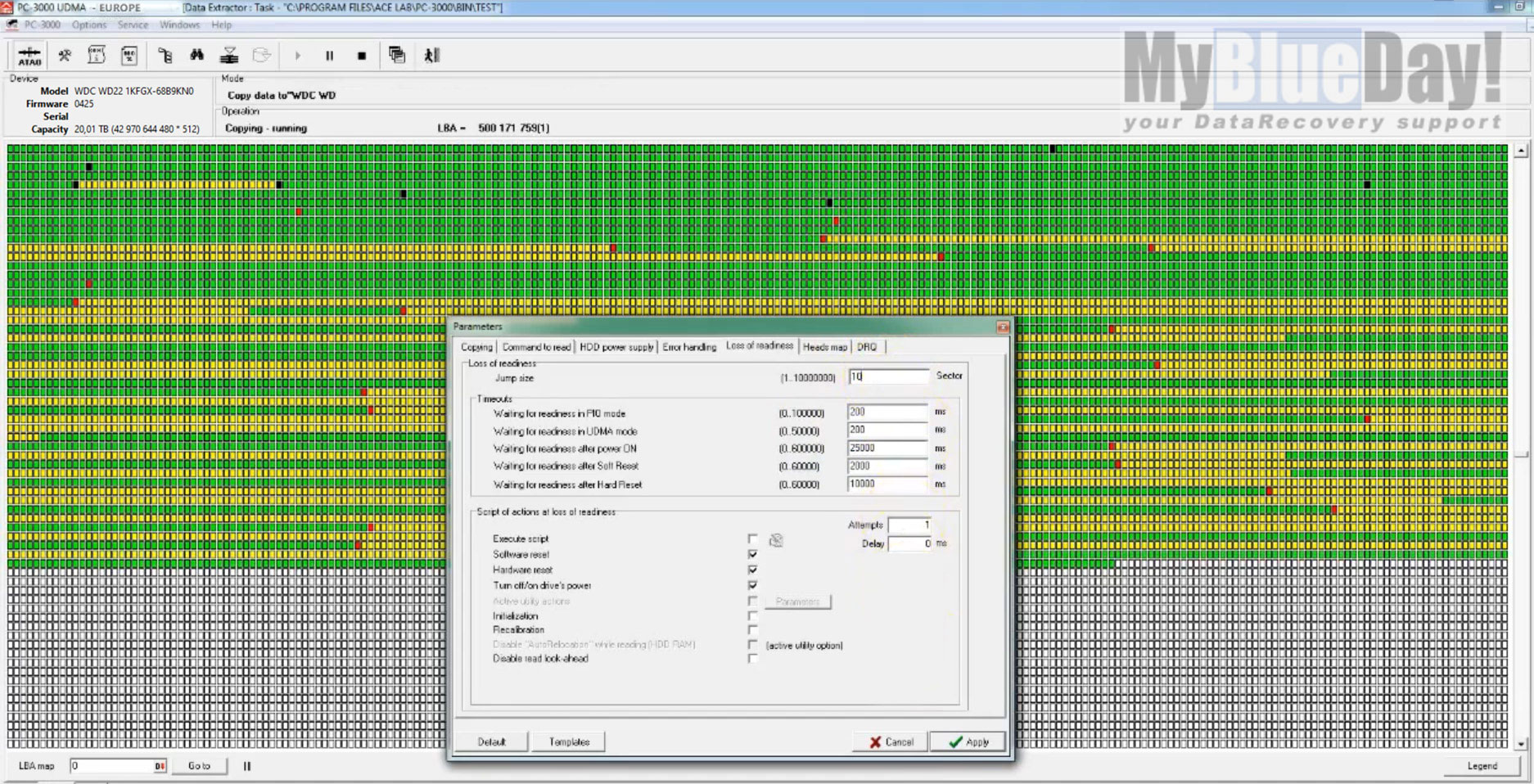
Obrázek 2.: změna nastavení "timeoutů" a tzv. "skipsize", což je velikost přeskakované oblasti v případě, že se během čtení narazí na nečitelnou oblast.
Abychom mohli pokračovat ve čtení, je nutné provést další nezbytný krok. Upravit podle potřeby časové limity čtení, také změnit velikost oblasti, kterou disk při čtení přeskočí v případě, že narazí na sektory, které nelze správně a v časových limitech přečíst. Tato místa samozřejmě nezůstanou nepřečtená celá. Aplikace se bude snažit následně tato místa dočítat v reverzně, tzn. od konce takové oblasti k prvnímu skutečně nečitelnému sektoru. Toto nastavení by ovšem k úspěšnému a efektivnímu čtení dat z poškozeného disku nestačilo. Vzhledem k tomu, že jsme během diagnostiky usoudili, že je masivně poškozen pouze jeden povrch datové plotny a ostatní jsou v dobrém stavu, změníme strategii čtení a vytvoříme tzv. head map, neboli divně česky, mapu čtecích hlav.
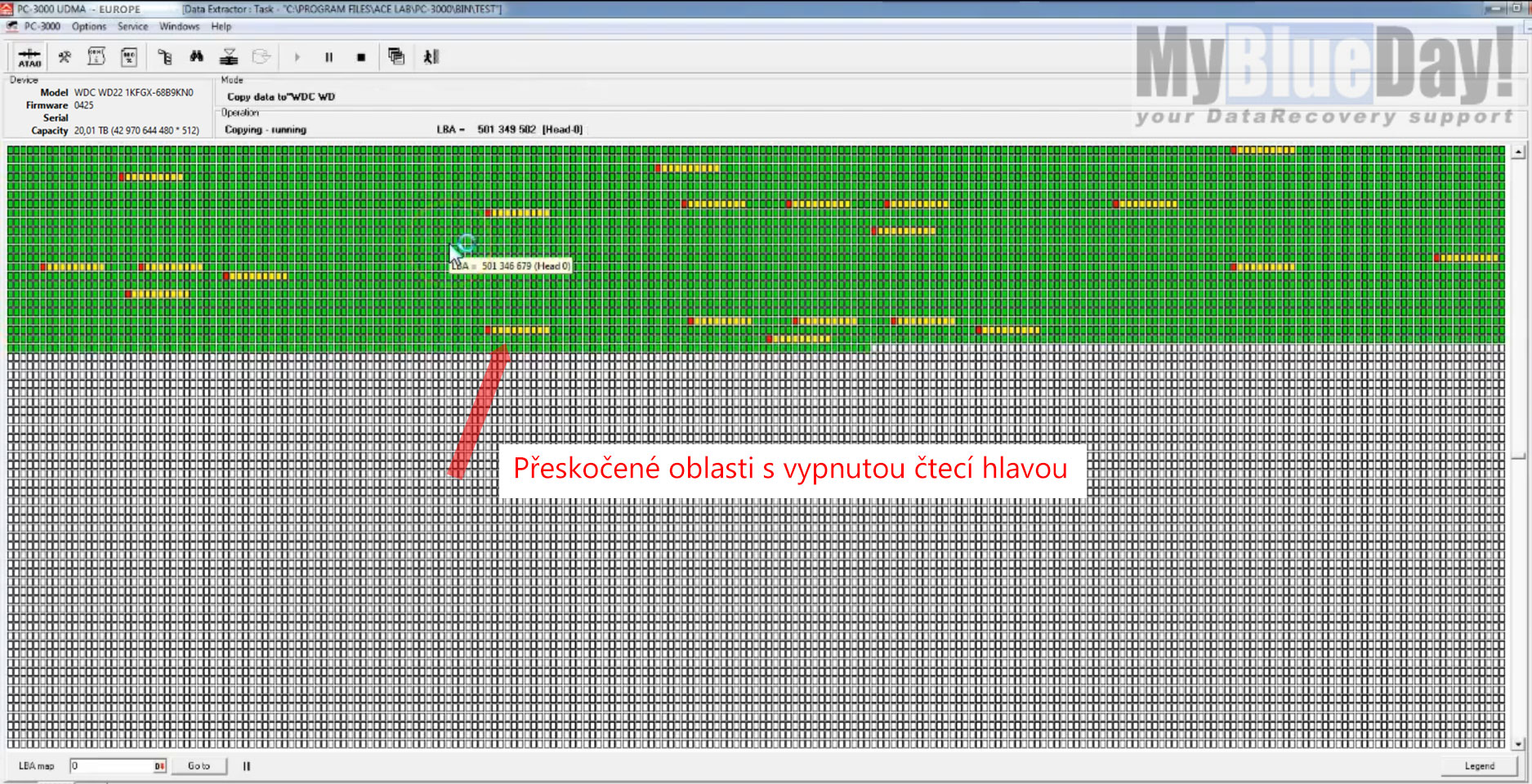
Obrázek 3.: zobrazení situace čtení vadného disku s vypnutou čtecí hlavou
Tato skvělá funkce velmi zjednodušeně zjistí, které sektory na disku se čtou kterou čtecí / zapisovací hlavou a následně vytvoří mapu, pomocí které můžeme deaktivovat konkrétní hlavy tak, abychom se vyhnuli čtení defektních oblastí, které jsou v tomto případě čteny jednou hlavou na jednom poškozeném povrchu plotny. Jak vidíte na přiloženém obrázku 3, pokud aplikujeme headmap v aktuálním případě, výrazně se zvýší výtěžnost přečtených dat, rychlost čtení je však stále poměrně neuspokojivá. V každém případě máme nyní poměrně slušný přehled o denzitě poškození. Následný krok by měl vést k výraznému zvýšení rychlosti čtení. Provedeme deaktivaci čtecí hlavy, která je zodpovědná za čtení vadné datové plotny. Výsledek této změny vidíte na obrázku níže.
Obrázek 4.: Konzistentní čtení dat po správném nastavení časových limitů, po vytvoření head map a deaktivaci čtecí hlavy
Jakmile jsme provedli deaktivaci čtecí hlavy, disk není ve svém čtení "bržděn" snahou o čtení degradovaných oblastí a rychlost čtení se naprosto zásadně zvýšila. Na ostatních plotnách detekujeme pouze nahodilé vadné sektory, jejichž ztráta má však vzhledem k velikosti disku marginální charakter. Nyní přeskočíme cca 30 hodin čtení. Jakmile jsou přečtené všechny zdravé plotny, je se potřeba začít věnovat té poslední. Nyní naopak provedeme deaktivaci všech čtecích / zapisovacích hlav disku, které již splnily svůj účel a naopak aktivujeme poslední čtecí hlavu, která se bude snažit číst obsah poslední poškozené datové plotny. Nastává poměrně náročná a piplavá práce analyzovat, která místa jsou na dané plotně poškozena nejvíce (v jakém rozmezí sektorů) a v první řadě se opět zaměřit na čtení těch částí disku, které nejsou poškozené vůbec, nebo minimálně. Následně se je třeba vracet do nedočtených míst a intenzivním dočítáním se snažit vyčíst maximum možného obsahu. Vždy je třeba počítat s tím, že pevné disky v tomto stavu podléhají průběžné degradaci, tzn. čím déle a intenzivněji takový disk čteme, tím se jeho stav bude více zhoršovat. Proto je vždy naprosto nutné zvolit takový způsob obnovy, který zaručí, že i z harddisku ve špatném stavu vyčteme minimálně část validního obsahu. Pravda ovšem je, že ne vždy se to musí podařit. Fyzika má své jasné mantinely. A pro zajímavost, po cca dalších 50 hodinách čtení jsme z disku vyčetli celkem 98% bitového obsahu. To není vůbec špatné. Bohužel ale, jsme pouze v časti cesty. Nyní nás čeká snaha obnovit data na RAID poli.
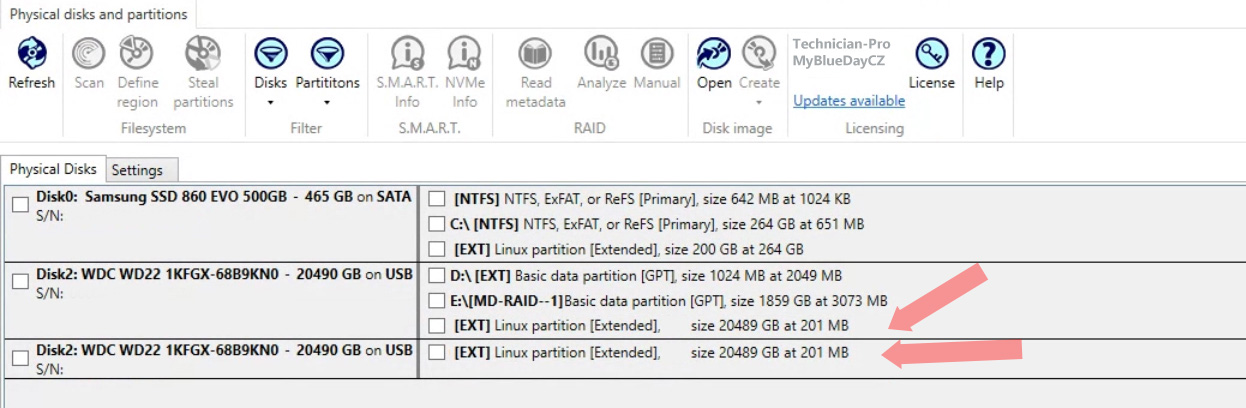
Obrázek 5.: Specializovaný software určený pro rekonstrukci RAID polí detekuje oba disky, na kterých jsou vytvořené bitové kopie z disků zdrojových.
V této fázi, kdy máme k dispozici dva zdravé disky obsahující maximum původních dat, zkusíme složit původní diskové pole. Dle sdělení zákazníka víme, že mělo být pole v konfiguraci RAID 0, což se potvrdilo již během diagnostiky. Také víme, že byl na diskovém poli použitý souborový systém EXT4. Po připojení k aplikaci, kterou využíváme pro pokročilou práci s poškozenými RAID detekujeme fyzicky oba disky, automatická detekce logického svazku a nalezení oddílu však selhala. To znamená, že během výpadku pole došlo k rozpadu svazku diskového pole, k poškození souborového systému a nebo jsme během práce na vadném disku nevyčetli veškerá data potřebná pro složení svazku. Pro zjištění konfigurace RAID svazku bychom mohli postupovat metodou pokus omyl, my však v tomto případě využijeme technologie analýzy dat aplikující postupy heuristiky a entropie.
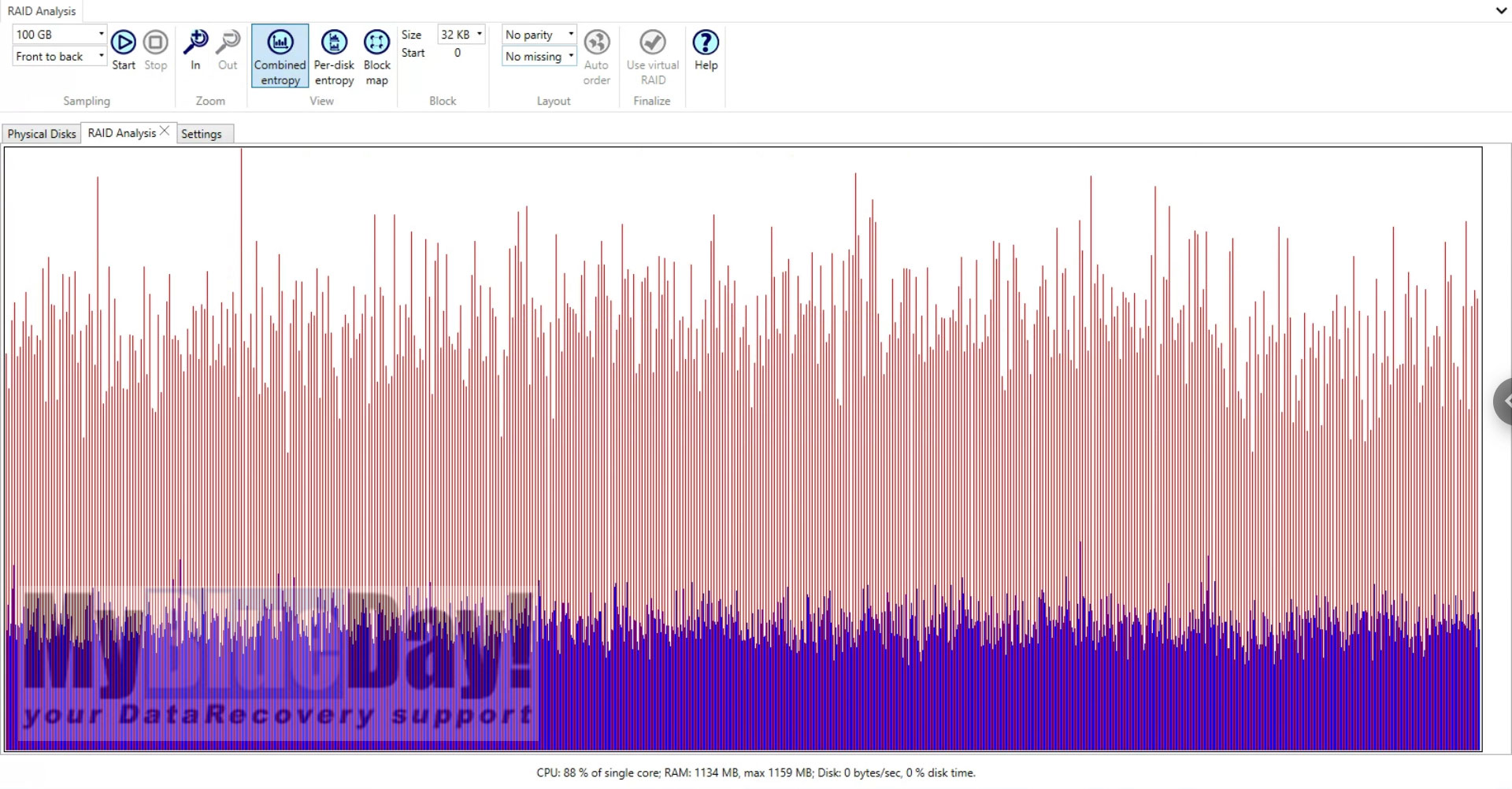
Obrázek 6.: Použití metody entropie a heuristiky pro detekci konfigurace diskového pole
Analýza entropie se obvykle používá pro disky pocházející z pole RAID s neznámým nastavením. Analýza entropie RAID pole umožňuje získat více informací o konfiguraci RAID, které mohou výrazně zúžit počet variant pro automatickou i ruční obnovu RAID pole. Pro správné použití analýzy entropie je třeba vybírat disk, které jsou členy RAID, a to vždy jednotlivě, nikoli RAID jako celek. Po nastavení aplikace a definici disků necháme vyhledávat entropii což nám pomůže získat více informací o daném RAID. Obecně je však tento způsob analýzy primárně používaný v případě rozpadu RAID polí obsahující paritní data, jako je RAID 5, RAID 6 atp.
Během analýzy entropie prohledáváme a zpracováváme data na všech vybraných zařízeních od začátku až do konce nejmenšího zařízení. Důležité je, že se entropie přepočítává a upravuje při každé změně počtu disků nebo velikosti bloku. Analýza a detekce entropie je užitečným nástrojem pro různé úlohy obnovy RAID, vyžaduje však pokročilé znalosti pro správné nastavení a interpretaci výsledků. V tomto konkrétním případě byla nalezena možná konfigurace pole po cca 48 hodinách.

Obrázek 7.: úspěšná detekce složeného svazku RAID 0 o celkové fyzické velikosti 44TB a souborovým systémem EXT4.
V okamžiku, kdy jsme získali validní přístup k celému svazku, bylo s ohledem na bezpečnost vhodné vytvořit obraz celého takto složeného pole. Vzhledem k velikosti finálního obrazu (cca 44TB) jsme byli nuceni vytvořit dostatečně velký prostor formou dalšího RAID pole. Použili jsme tedy 4x HDD o kapacitě 16TB složených do svazku RAID 5. Tato konfigurace nám umožnila vytvořit volný diskový prostor o velikosti 48TB společně s 16TB ochranné parity, na který bylo možné celý obraz diskového pole uložit. A proč? Neustále je nutné pracovat s tím, že kterýkoliv z disků, na kterém jsou vytvořeny bitové kopie může selhat. Je tedy naprosto nezbytné udržovat zálohy pracovních dat ideálně v nejaktuálnější podobě. V této fázi jsme tedy pro práci využili 2x22TB pro vytvořeni image disků + 4x16TB pro uložení obrazu sestaveného RAIDu. Celkem jsme tedy na 108TB úložného prostoru. Abychom šetřili čas, provádíme během ukládání obrazu pole skenování souborového systému, abychom měli jistotu, že dokážeme obnovit veškerá dostupná data, včetně těch, která mohou být z libovolného důvodu nezařaditelná do platné adresářové struktury. Proto je v těchto případech i přes nutnost další procedury sken validity a souborového systému nutností.
Vyčtení obnovených dat a jejich kontrola
Závěrečná fáze obnovy dat z diskového pole je uložení vlastních a funkčních souborů do ideální adresářové struktury na nosič, z kterého budou data prezentována majiteli a odkud je bude možné uložit na datové zařízení pro expedici dat. Z obnovené adresářové struktury bylo zřejmé, že je na disku alokováno cca 25TB dat. Vzhledem k tomu, že aktuálně nemáme k dispozici volný disk o kapacitě 28TB, vytvoříme si v našem oblíbeném externím boxu OWC Gemini další diskové pole, tentokrát již na RAID 0. Opět dva 16TB disky (cenové přístupné Toshiby) nám v této konfiguraci dají potřebných cca 30TB prostoru. Výhoda námi používaného boxu OWC je použití velmi rychlého rozhraní Thunderbolt 3, které nás díky propustnosti absolutně neomezuje. Po vykopírování kompletní obnovy jsme data pomocí zabezpečeného vzdáleného přístupu odprezentovali majiteli.
A jaká byla ve finále úspěšnost záchrany dat? Vzhledem k tomu, že disk obsahoval z větší části obsahově rozměrná audiovizuální data v kodeku H265 (a samozřejmě mnoho dalších typů souborů), je statisticky pravděpodobné, že i jeden nepřečtený sektor může způsobit poškození obsáhlého souboru. Celkem jsme z celkových cca 25TB dat evidovali cca 50GB dat obsahujících chyby. My taková data považujeme za neobnovitelná. Naštěstí je však použitý videokodek poměrně robustní proti drobné chybovosti. Tzn. že minimální chybovost nemá vliv na dekomprimaci a běh souboru. Proto lze takový soubor i v případě že obsahuje chyby velmi často bez problému použít a případě v postprodukci dále zpracovat. Narozdíl např. od souborů typu JPG, DOC(x) atp., kdy i malá chyba zapříčiní selhání otevření souboru. Úspěšnost záchrany dat tak byla z pohledu zákazníka na úrovni cca 99%, což považujeme v tomto případě za vynikající výsledek. A finální součet. Pro bezpečnou záchranu dat z poškozeného RAID 0 o kapacitě 44 TB bylo zapotřebí celkem 138TB diskového prostoru.